2026
SEAL-pose: Enhancing 3D Human Pose Estimation via a Learned Loss for Structural Consistency
Yeonsung Kim*, Junggeun Do*, Seunguk Do, Sangmin Kim, Jaesik Park, Jay-Yoon Lee (* equal contribution)
arXiv preprint (earlier version presented at ICCV 2025 Workshop SP4V)
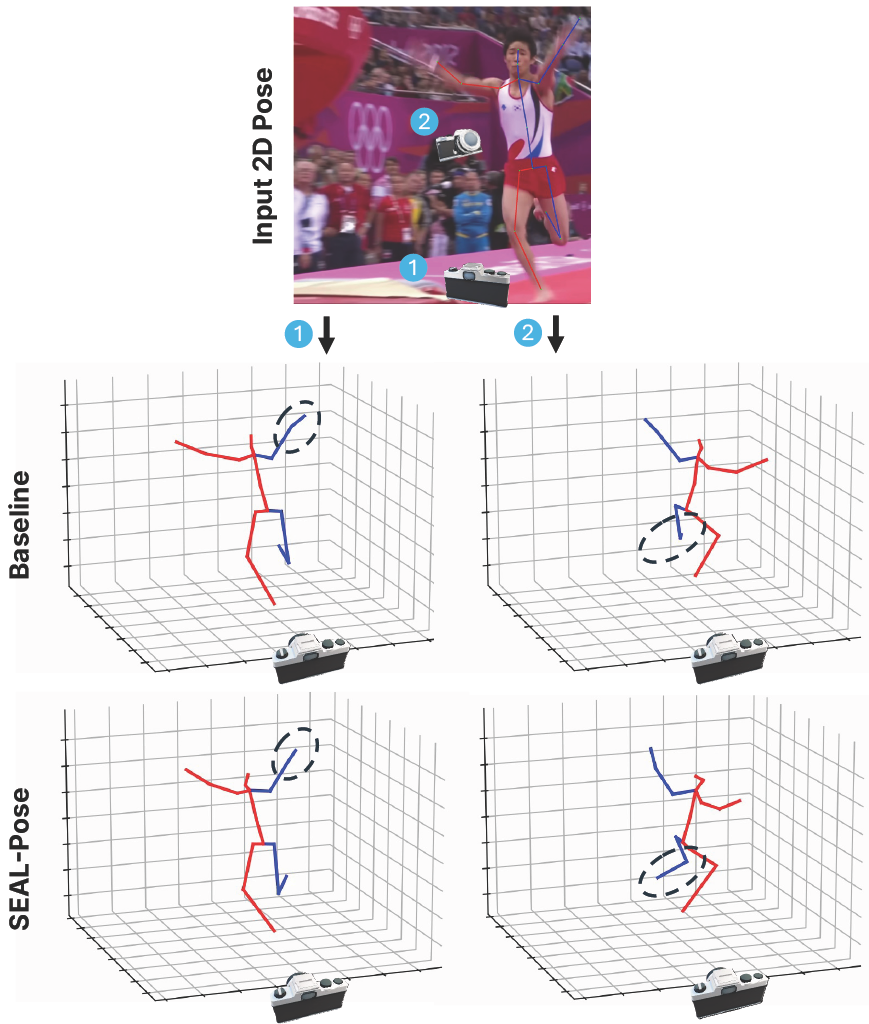
3D human pose estimation (HPE) is characterized by intricate local and global dependencies among joints. Conventional supervised losses are limited in capturing these correlations because they treat each joint independently. Previous studies have attempted to promote structural consistency through manually designed priors or rule-based constraints; however, these approaches typically require manual specification and are often non-differentiable, limiting their use as end-to-end training objectives. We propose SEAL-pose, a data-driven framework in which a learnable loss-net trains a pose-net by evaluating structural plausibility. Rather than relying on hand-crafted priors, our joint-graph-based design enables the loss-net to learn complex structural dependencies directly from data. Extensive experiments on three 3D HPE benchmarks with eight backbones show that SEAL-pose reduces per-joint errors and improves pose plausibility compared with the corresponding backbones across all settings. Beyond improving each backbone, SEAL-pose also outperforms models with explicit structural constraints, despite not enforcing any such constraints. Finally, we analyze the relationship between the loss-net and structural consistency, and evaluate SEAL-pose in cross-dataset and in-the-wild settings.
SEAL-pose: Enhancing 3D Human Pose Estimation via a Learned Loss for Structural Consistency
Yeonsung Kim*, Junggeun Do*, Seunguk Do, Sangmin Kim, Jaesik Park, Jay-Yoon Lee (* equal contribution)
arXiv preprint (earlier version presented at ICCV 2025 Workshop SP4V)
3D human pose estimation (HPE) is characterized by intricate local and global dependencies among joints. Conventional supervised losses are limited in capturing these correlations because they treat each joint independently. Previous studies have attempted to promote structural consistency through manually designed priors or rule-based constraints; however, these approaches typically require manual specification and are often non-differentiable, limiting their use as end-to-end training objectives. We propose SEAL-pose, a data-driven framework in which a learnable loss-net trains a pose-net by evaluating structural plausibility. Rather than relying on hand-crafted priors, our joint-graph-based design enables the loss-net to learn complex structural dependencies directly from data. Extensive experiments on three 3D HPE benchmarks with eight backbones show that SEAL-pose reduces per-joint errors and improves pose plausibility compared with the corresponding backbones across all settings. Beyond improving each backbone, SEAL-pose also outperforms models with explicit structural constraints, despite not enforcing any such constraints. Finally, we analyze the relationship between the loss-net and structural consistency, and evaluate SEAL-pose in cross-dataset and in-the-wild settings.
2024

ContrastiveMix: Overcoming Code-Mixing Dilemma in Cross-Lingual Transfer for Information Retrieval
Junggeun Do, Jaeseong Lee, Seung-won Hwang
NAACL 2024 Oral
Multilingual pretrained language models (mPLMs) have been widely adopted in cross-lingual transfer, and code-mixing has demonstrated effectiveness across various tasks in the absence of target language data. Our contribution involves an in-depth investigation into the counterproductive nature of training mPLMs on code-mixed data for information retrieval (IR). Our finding is that while code-mixing demonstrates a positive effect in aligning representations across languages, it hampers the IR-specific objective of matching representations between queries and relevant passages. To balance between positive and negative effects, we introduce ContrastiveMix, which disentangles contrastive loss between these conflicting objectives, thereby enhancing zero-shot IR performance. Specifically, we leverage both English and code-mixed data and employ two contrastive loss functions, by adding an additional contrastive loss that aligns embeddings of English data with their code-mixed counterparts in the query encoder. Our proposed ContrastiveMix exhibits statistically significant outperformance compared to mDPR, particularly in scenarios involving lower linguistic similarity, where the conflict between goals is more pronounced.
ContrastiveMix: Overcoming Code-Mixing Dilemma in Cross-Lingual Transfer for Information Retrieval
Junggeun Do, Jaeseong Lee, Seung-won Hwang
NAACL 2024 Oral
Multilingual pretrained language models (mPLMs) have been widely adopted in cross-lingual transfer, and code-mixing has demonstrated effectiveness across various tasks in the absence of target language data. Our contribution involves an in-depth investigation into the counterproductive nature of training mPLMs on code-mixed data for information retrieval (IR). Our finding is that while code-mixing demonstrates a positive effect in aligning representations across languages, it hampers the IR-specific objective of matching representations between queries and relevant passages. To balance between positive and negative effects, we introduce ContrastiveMix, which disentangles contrastive loss between these conflicting objectives, thereby enhancing zero-shot IR performance. Specifically, we leverage both English and code-mixed data and employ two contrastive loss functions, by adding an additional contrastive loss that aligns embeddings of English data with their code-mixed counterparts in the query encoder. Our proposed ContrastiveMix exhibits statistically significant outperformance compared to mDPR, particularly in scenarios involving lower linguistic similarity, where the conflict between goals is more pronounced.